









其实前天就已经做好了工具,只是不知道要不要放出来。看到现在网上放流的机翻已经这么多,即使放出来也不会引起太大动乱,所以就果断把这个项目写进博客,全当为大家多提供些许玩具吧。
首先感谢Leohearts负责了解包封包。
项目地址:https://github.com/cmd2001/mangekyo5_Chs
GitHub链接放出来,知道我想要什么了吧。
求Star!求Watch!求Fork!一声不吭只管clone的白嫖怪最讨厌了~
免责声明:本项目仅包含翻译制作工具,不包含游戏本体。请从合法正规手段获取游戏本体后使用本项目辅助翻译。
使用方法:
首先感谢hz86/filepack,请使用这个工具完成解包封包。
接着,填写百度翻译API内容,并于指定内容运行翻译脚本。(具体用法readme写得很清楚)
翻译过程截图:

效果图:



为什么出了第一幕外截图都是莲华?莲华我老婆~不接受反驳。
(总感觉上面那句话很适合我)

由于只改动了文本,选项当然是没有汉化的啦~
关于字体一大一小的问题,是由于原版程序默认日文字体,缺少简体字符,字体渲染fallback所致。更改字体即可:
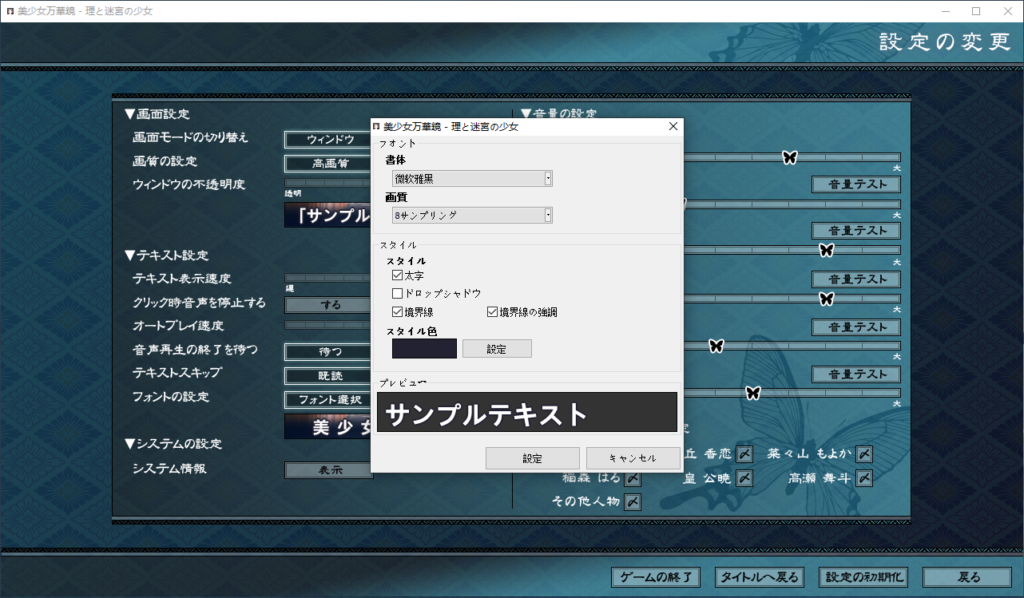
关于本工具的具体实现,无非就是解析文本+逐句翻译。这里感谢Leohearts帮我完成文本解析工作。
work.py是该翻译器的主要部分,其工作原理为从文件读入句子,空格分离,跳过无需翻译的指令语句,去除对话中的注音语句,并将剩余部分利用百度翻译API进行翻译。
源码如下:
import argparse
from BaiduTrans import translate
import time
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--filePath', type=str)
arguments = parser.parse_args()
file = open(arguments.filePath, 'r', encoding='utf-16')
data = file.read().split('\n')
file.close()
out = []
def removeRB(s):
ret = ''
i = 0
while i < len(s):
if s[i] != '[':
ret = ret + s[i]
else:
j = i
while s[j] != ']':
j = j + 1
s2 = s[i + 1:j - 1]
ret = ret + s2.split(',')[1]
i = j
i = i + 1
return ret
for x in data:
if x != '' and x[0] != '%' and x[0] != '^' and x[0] != '@' and x[0] != '\\' and x[0] != '【':
y = translate(removeRB(x)).replace('莲花', '莲华').replace('荷花', '莲华')
print(y)
out.append(y)
time.sleep(0.1)
else:
out.append(x)
file = open(arguments.filePath, 'w', encoding='utf-16')
for x in out:
file.write(x + '\n')
关于replace('莲花', '莲华').replace('荷花', '莲华'),只要老婆名字译对了其余错再多了不管啦~
BaiduTrans.py,参考官方API实现翻译函数:
import http.client
import hashlib
import urllib
import random
import json
def translate(q):
appid = '' # Your baidu translation API Appid
secretKey = '' # Your baidu translation API Key
httpClient = None
myurl = '/api/trans/vip/translate'
fromLang = 'jp'
toLang = 'zh'
salt = random.randint(32768, 65536)
sign = appid + q + str(salt) + secretKey
sign = hashlib.md5(sign.encode()).hexdigest()
myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str(
salt) + '&sign=' + sign
httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')
httpClient.request('GET', myurl)
response = httpClient.getresponse()
result_all = response.read().decode("utf-8")
result = json.loads(result_all)
return result['trans_result'][0]['dst']
由于百度翻译API有调用频率限制,所以work.py中不得不sleep。不过百度翻译处理东亚语言确实比Google翻译更好一些,不知道DeepL效果怎样(DeepL python3 API好像不支持翻译日文中文?)
最后,有一张图我不知该不该发:

开玩笑,大家当然要注意身体啦~
评论~ 2 条评论
DeepL效果确实好, 论文洗稿神器(大雾)下次试试这个?
蛇蛇,谢了